
Mark Perry writes in his Carpe Diem blog of the "very large, tsunami of creative destruction called The Open Textbook Effect" – powered by projects like OpenStax – that has driven down college textbook prices for the first time in 40 years.
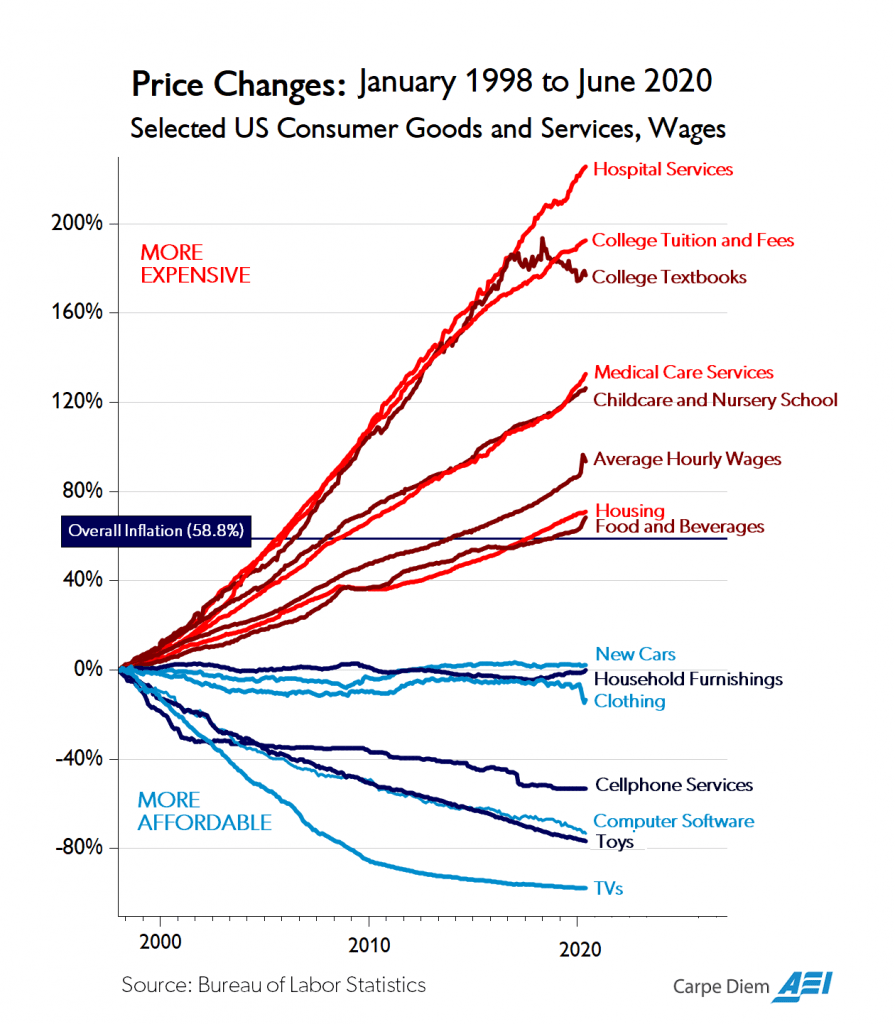
Mark Perry writes in his Carpe Diem blog of the "very large, tsunami of creative destruction called The Open Textbook Effect" – powered by projects like OpenStax – that has driven down college textbook prices for the first time in 40 years.
 Open educational resources publisher OpenStax has received $12.5 million in funding to develop dozens of new free and open-licensed textbook titles as part of a program that will double its current catalog of 42 textbooks.
Open educational resources publisher OpenStax has received $12.5 million in funding to develop dozens of new free and open-licensed textbook titles as part of a program that will double its current catalog of 42 textbooks.
“Nine years ago, we dreamed about solving the textbook affordability and access crisis for students,” said Richard Baraniuk, the Victor E. Cameron Professor of Electrical and Computer Engineering at Rice and founder and director of OpenStax. “Now, with this tremendous investment in open education, we will be able to not only accelerate educational access for tens of millions of students but also drive innovation in high-quality digital learning, which has become commonplace due to Covid-19.”
Read more in the press release and Inside Higher Education.
Less than a decade after publishing its first free, openly licensed textbook, OpenStax — Rice’s educational technology initiative — has saved students $1.2 billion.
Driven by the belief that everyone should have access to knowledge, OpenStax has published 42 titles for college and high school courses across science, math, social sciences, business and the humanities disciplines since 2012. It has served over 14 million students with its resources, with more than 36,000 instructors from across the world adopting an OpenStax textbook. Every book in its library is available free — forever — to students and independent learners.
Read the press release

![]()
Rice DSP group faculty Richard Baraniuk will be leading a team of engineers, computer scientists, mathematicians, and statisticians on a five-year ONR MURI project to develop a principled theory of deep learning based on rigorous mathematical principles. The team includes:
International collaborators include the Alan Turing and Isaac Newton Institutes in the UK.
 The DSP group will present two papers at the International Conference on Artificial Intelligence and Statistics (AISTATS) conference in June 2020 in Palermo, Sicily, Italy
The DSP group will present two papers at the International Conference on Artificial Intelligence and Statistics (AISTATS) conference in June 2020 in Palermo, Sicily, Italy
 An article on OpenStax by reporter Rebecca Koenig appears in the Oct 24, 2019 edition of EdSurge.
An article on OpenStax by reporter Rebecca Koenig appears in the Oct 24, 2019 edition of EdSurge.
D. LeJeune, H. Javadi, R. G. Baraniuk, "The Implicit Regularization of Ordinary Least Squares Ensembles," arxiv.org/abs/1910.04743, 10 October 2019.
Ensemble methods that average over a collection of independent predictors that are each limited to a subsampling of both the examples and features of the training data command a significant presence in machine learning, such as the ever-popular random forest, yet the nature of the subsampling effect, particularly of the features, is not well understood. We study the case of an ensemble of linear predictors, where each individual predictor is fit using ordinary least squares on a random submatrix of the data matrix. We show that, under standard Gaussianity assumptions, when the number of features selected for each predictor is optimally tuned, the asymptotic risk of a large ensemble is equal to the asymptotic ridge regression risk, which is known to be optimal among linear predictors in this setting. In addition to eliciting this implicit regularization that results from subsampling, we also connect this ensemble to the dropout technique used in training deep (neural) networks, another strategy that has been shown to have a ridge-like regularizing effect.
Above: Example (rows) and feature (columns) subsampling of the training data X used in the ordinary least squares fit for one member of the ensemble. The i-th member of the ensemble is only allowed to predict using its subset of the features (green). It must learn its parameters by performing ordinary least squares using the subsampled examples of (red) and the subsampled examples (rows) and features (columns) of X (blue, crosshatched).
![]() From an article in Campus Technology: This year, 56% of all colleges and universities in the United States are using free textbooks from OpenStax in at least one course. That equates to 5,900-plus institutions and nearly 3 million students.
From an article in Campus Technology: This year, 56% of all colleges and universities in the United States are using free textbooks from OpenStax in at least one course. That equates to 5,900-plus institutions and nearly 3 million students.
OpenStax provides textbooks for 36 college and Advanced Placement courses. Students can access the materials for free digitally (via browser, downloadable PDF or recently introduced OpenStax + SE mobile app), or pay for a low-cost print version. Overall, students are saving more than $200 million on their textbooks in 2019, and have saved a total of $830 million since OpenStax launched in 2012.
Future plans for the publisher include the rollout of Rover by OpenStax, an online math homework tool designed to give students step-by-step feedback on their work. OpenStax also plans to continue its research initiatives on digital learning, using cognitive science-based approaches and the power of machine learning to improve how students learn.

Writes Chris Taylor from Reuters in Moneysaving 101: Four Ways to Cut College Textbook Costs, "While sky-high U.S. college tuition might be the headline number, here is a sneaky little figure that might surprise you: the cost of textbooks." See what OpenStax is doing about the crisis here.
![]()
An article in the 28 July 2019 Wall Street Journal, "A Key Reason the Fed Struggles to Hit 2% Inflation: Uncooperative Prices" discusses the disruptive impact on the college textbook market of the free and open-source textbooks provided by OpenStax . Read online at Morningstar.com.