J. K. Adams, V. Boominathan, B. W. Avants, D. G. Vercosa, F. Ye, R. G. Baraniuk, J. T. Robinson, A. Veeraraghavan, “Single-Frame 3D Fluorescence Microscopy with Ultraminiature Lensless FlatScope,” Science Advances, Vol. 3, No. 12, 8 December 2017.
Abstract: Modern biology increasingly relies on fluorescence microscopy, which is driving demand for smaller, lighter, and cheaper microscopes. However, traditional microscope architectures suffer from a fundamental trade-off: As lenses become smaller, they must either collect less light or image a smaller field of view. To break this fundamental trade-off between device size and performance, we present a new concept for three-dimensional (3D) fluorescence imaging that replaces lenses with an optimized amplitude mask placed a few hundred micrometers above the sensor and an efficient algorithm that can convert a single frame of captured sensor data into high-resolution 3D images. The result is FlatScope: perhaps the world’s tiniest and lightest microscope. FlatScope is a lensless microscope that is scarcely larger than an image sensor (roughly 0.2 g in weight and less than 1 mm thick) and yet able to produce micrometer-resolution, high–frame rate, 3D fluorescence movies covering a total volume of several cubic millimeters. The ability of FlatScope to reconstruct full 3D images from a single frame of captured sensor data allows us to image 3D volumes roughly 40,000 times faster than a laser scanning confocal microscope while providing comparable resolution. We envision that this new flat fluorescence microscopy paradigm will lead to implantable endoscopes that minimize tissue damage, arrays of imagers that cover large areas, and bendable, flexible microscopes that conform to complex topographies.
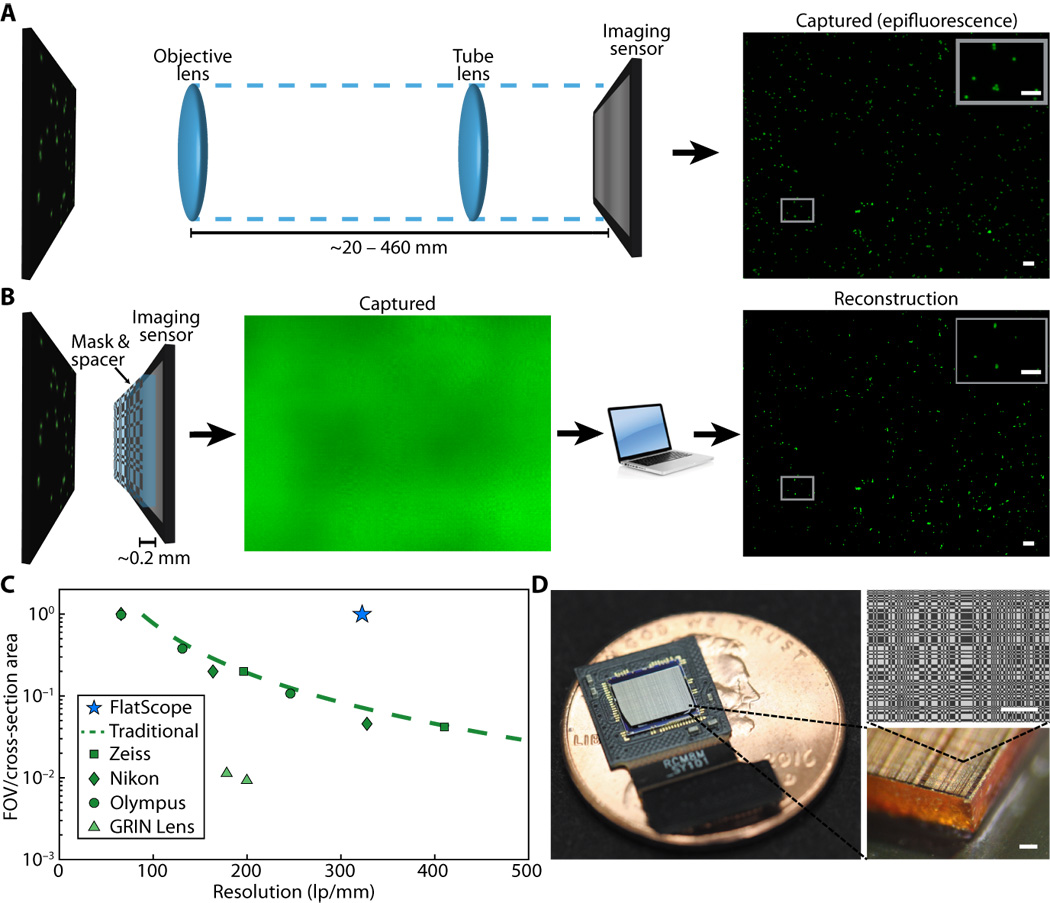
Fig. 1. Traditional microscope versus FlatScope. (A) Traditional microscopes capture the scene through an objective and tube lens (~20 to 460 mm), resulting in a quality image directly on the imaging sensor. (B) FlatScope captures the scene through an amplitude mask and spacer (~0.2 mm) and computationally reconstructs the image. Scale bars, 100 μm (inset, 50 μm). (C) Comparison of form factor and resolution for traditional lensed research microscopes, GRIN lens microscope, and FlatScope. FlatScope achieves high-resolution imaging while maintaining a large ratio of FOV relative to the cross-sectional area of the device (see Materials and Methods for elaboration). Microscope objectives are Olympus MPlanFL N (1.25×/2.5×/5×, NA = 0.04/0.08/0.15), Nikon Apochromat (1×/2×/4×, NA = 0.04/0.1/0.2), and Zeiss Fluar (2.5×/5×, NA = 0.12/0.25). (D) FlatScope prototype (shown without absorptive filter). Scale bars, 100 μm.


 Two workshops have been accepted for
Two workshops have been accepted for