
Thanks to Shashank Sonkar, CJ Barberan, and Pavan Kota of the DSP group for producing the RichB Academic Family Tree ca. 2019. The code is available here.
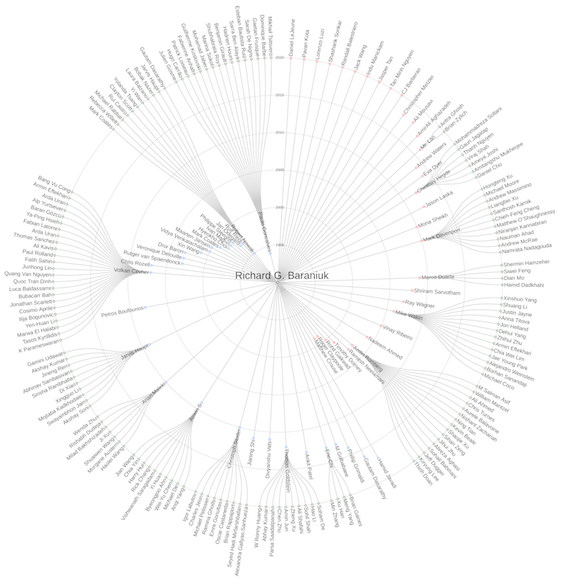
Thanks to Shashank Sonkar, CJ Barberan, and Pavan Kota of the DSP group for producing the RichB Academic Family Tree ca. 2019. The code is available here.
 DSP group members will be traveling en masse to New Orleans in May 2019 to present four regular papers at the International Conference on Learning Representations
DSP group members will be traveling en masse to New Orleans in May 2019 to present four regular papers at the International Conference on Learning Representations
 Two workshops have been accepted for NIPS in December 2018; more details soon on how to contribute:
Two workshops have been accepted for NIPS in December 2018; more details soon on how to contribute:
 This year, over 2.2 million students are saving an estimated $177 million by using free textbooks from OpenStax, the Rice University-based publisher of open educational resource materials. Since 2012, OpenStax's 29 free, peer-reviewed, openly licensed textbooks for the highest-enrolled high school and college courses have been used by more than 6 million students. This year, OpenStax added several new books to its library, including Biology for AP Courses, Introductory Business Statistics and second editions of its economics titles.
This year, over 2.2 million students are saving an estimated $177 million by using free textbooks from OpenStax, the Rice University-based publisher of open educational resource materials. Since 2012, OpenStax's 29 free, peer-reviewed, openly licensed textbooks for the highest-enrolled high school and college courses have been used by more than 6 million students. This year, OpenStax added several new books to its library, including Biology for AP Courses, Introductory Business Statistics and second editions of its economics titles.
OpenStax books are having a tangible, marketwide impact, according to a 2017 Babson Survey that found that “the rate of adoption of OpenStax textbooks among faculty teaching large-enrollment courses is now at 16.5%, a rate which rivals that of most commercial textbooks." "We're excited about the rapidly growing number of instructors making the leap to open textbooks," said OpenStax founder Richard Baraniuk, the Victor E. Cameron Professor of Electrical and Computer Engineering at Rice. "Our community is creating a movement that will make a big impact on college affordability. The success of open textbooks like OpenStax have ignited competition in the textbook market, and textbook prices are actually falling for the first time in 50 years."
Read the full press release
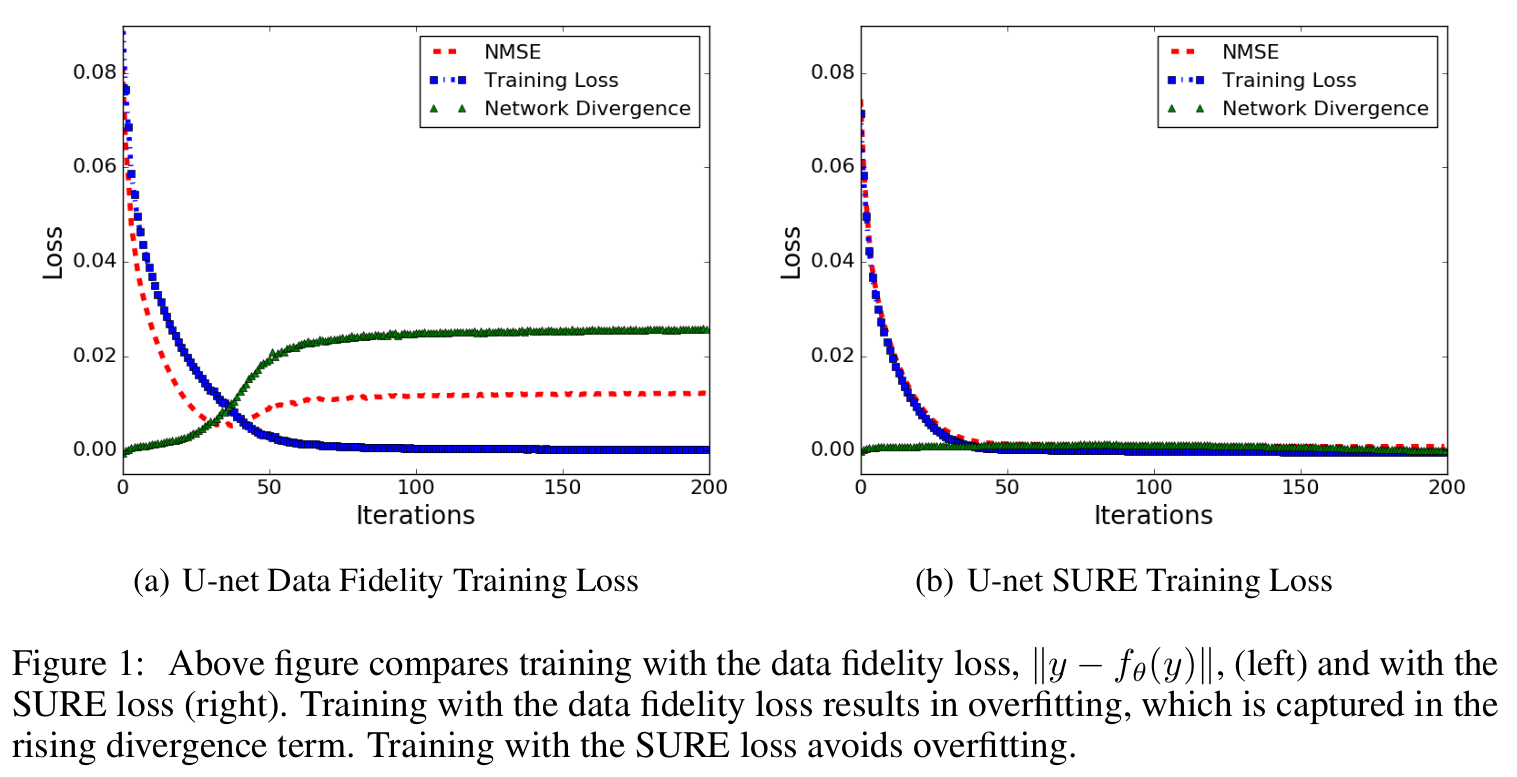
C. A. Metzler, A. Mousavi, R. Heckel, and R. G. Baraniuk, “Unsupervised Learning with Stein’s Unbiased Risk Estimator,” https://arxiv.org/abs/1805.10531, June 2018.
 Appearing today on NSF's Science360 News: Taking a closer look with a lens-free fluorescent microscope
Appearing today on NSF's Science360 News: Taking a closer look with a lens-free fluorescent microscope
Rice University engineers are building a flat microscope, called FlatScope (TM), and developing software that can decode and trigger neurons on the surface of the brain. The goal as part of a new government initiative is to provide an alternate path for sight and sound to be delivered directly to the brain. The project is part of a $65 million effort announced this week by the federal Defense Advanced Research Projects Agency (DARPA) to develop a high-resolution neural interface. Among many long-term goals, the Neural Engineering System Design (NESD) program hopes to compensate for a person's loss of vision or hearing by delivering digital information directly to parts of the brain that can process it.
 The 2006 TED talk explaining the vision behind the open-source, online education system Connexions (now called OpenStax) surpassed 1 million views on the TED Talks website. We've come a long way from the genesis of Connexions in 1999!
The 2006 TED talk explaining the vision behind the open-source, online education system Connexions (now called OpenStax) surpassed 1 million views on the TED Talks website. We've come a long way from the genesis of Connexions in 1999!

OpenStax’s market share in the college textbook market continues to grow rapidly. According to the latest Babson Survey Research Group Report on Open Educational Resources (OER), 16.5% of faculty who recently chose a new textbook for a large-enrollment introductory-level course adopted a textbook from OpenStax. This is up 50% over 2016’s adoption rate of 10.8%. The survey finds that OpenStax textbooks are being adopted for large-enrollment introductory courses at roughly the same rate as commercial textbooks.
J. K. Adams, V. Boominathan, B. W. Avants, D. G. Vercosa, F. Ye, R. G. Baraniuk, J. T. Robinson, A. Veeraraghavan, “Single-Frame 3D Fluorescence Microscopy with Ultraminiature Lensless FlatScope,” Science Advances, Vol. 3, No. 12, 8 December 2017.
Abstract: Modern biology increasingly relies on fluorescence microscopy, which is driving demand for smaller, lighter, and cheaper microscopes. However, traditional microscope architectures suffer from a fundamental trade-off: As lenses become smaller, they must either collect less light or image a smaller field of view. To break this fundamental trade-off between device size and performance, we present a new concept for three-dimensional (3D) fluorescence imaging that replaces lenses with an optimized amplitude mask placed a few hundred micrometers above the sensor and an efficient algorithm that can convert a single frame of captured sensor data into high-resolution 3D images. The result is FlatScope: perhaps the world’s tiniest and lightest microscope. FlatScope is a lensless microscope that is scarcely larger than an image sensor (roughly 0.2 g in weight and less than 1 mm thick) and yet able to produce micrometer-resolution, high–frame rate, 3D fluorescence movies covering a total volume of several cubic millimeters. The ability of FlatScope to reconstruct full 3D images from a single frame of captured sensor data allows us to image 3D volumes roughly 40,000 times faster than a laser scanning confocal microscope while providing comparable resolution. We envision that this new flat fluorescence microscopy paradigm will lead to implantable endoscopes that minimize tissue damage, arrays of imagers that cover large areas, and bendable, flexible microscopes that conform to complex topographies.
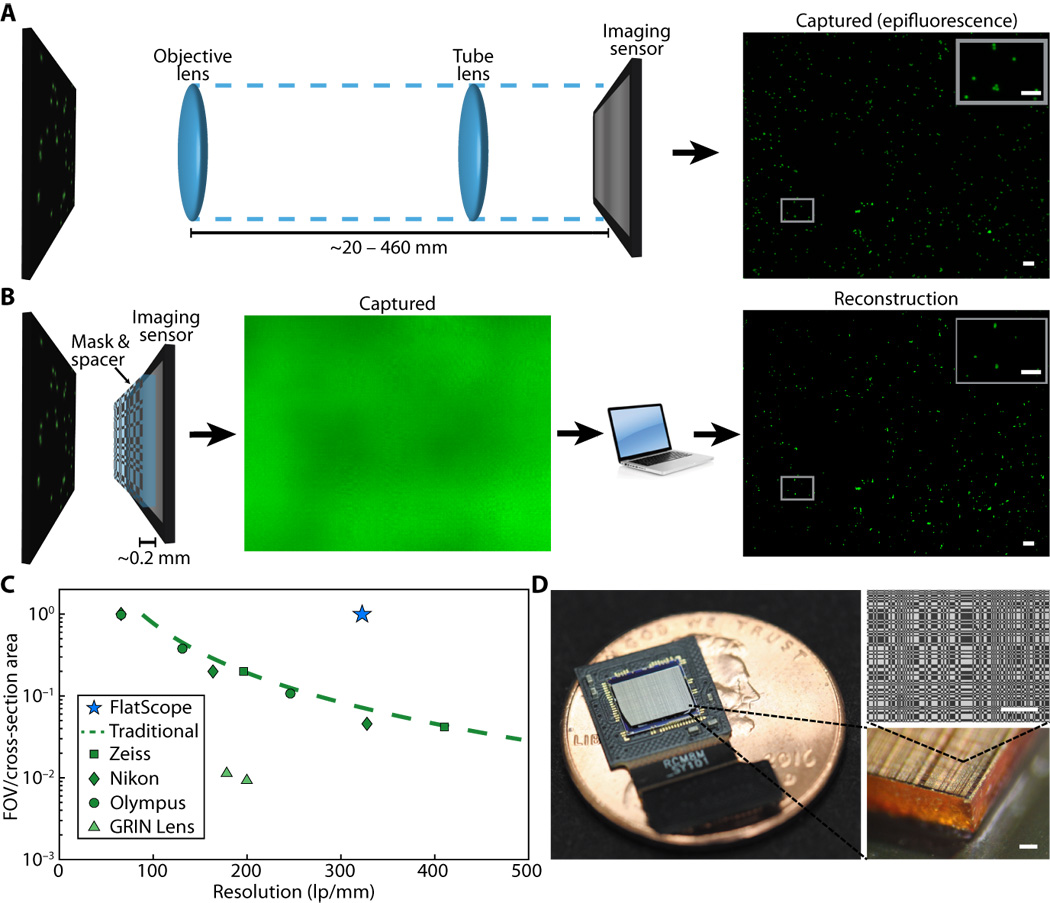
Fig. 1. Traditional microscope versus FlatScope. (A) Traditional microscopes capture the scene through an objective and tube lens (~20 to 460 mm), resulting in a quality image directly on the imaging sensor. (B) FlatScope captures the scene through an amplitude mask and spacer (~0.2 mm) and computationally reconstructs the image. Scale bars, 100 μm (inset, 50 μm). (C) Comparison of form factor and resolution for traditional lensed research microscopes, GRIN lens microscope, and FlatScope. FlatScope achieves high-resolution imaging while maintaining a large ratio of FOV relative to the cross-sectional area of the device (see Materials and Methods for elaboration). Microscope objectives are Olympus MPlanFL N (1.25×/2.5×/5×, NA = 0.04/0.08/0.15), Nikon Apochromat (1×/2×/4×, NA = 0.04/0.1/0.2), and Zeiss Fluar (2.5×/5×, NA = 0.12/0.25). (D) FlatScope prototype (shown without absorptive filter). Scale bars, 100 μm.
Mark Perry of the American Enterprise Institute posits that the long-term trend of rapidly increasing textbook prices might have finally been disrupted by market competition, partly by new textbook alternatives like OpenStax.
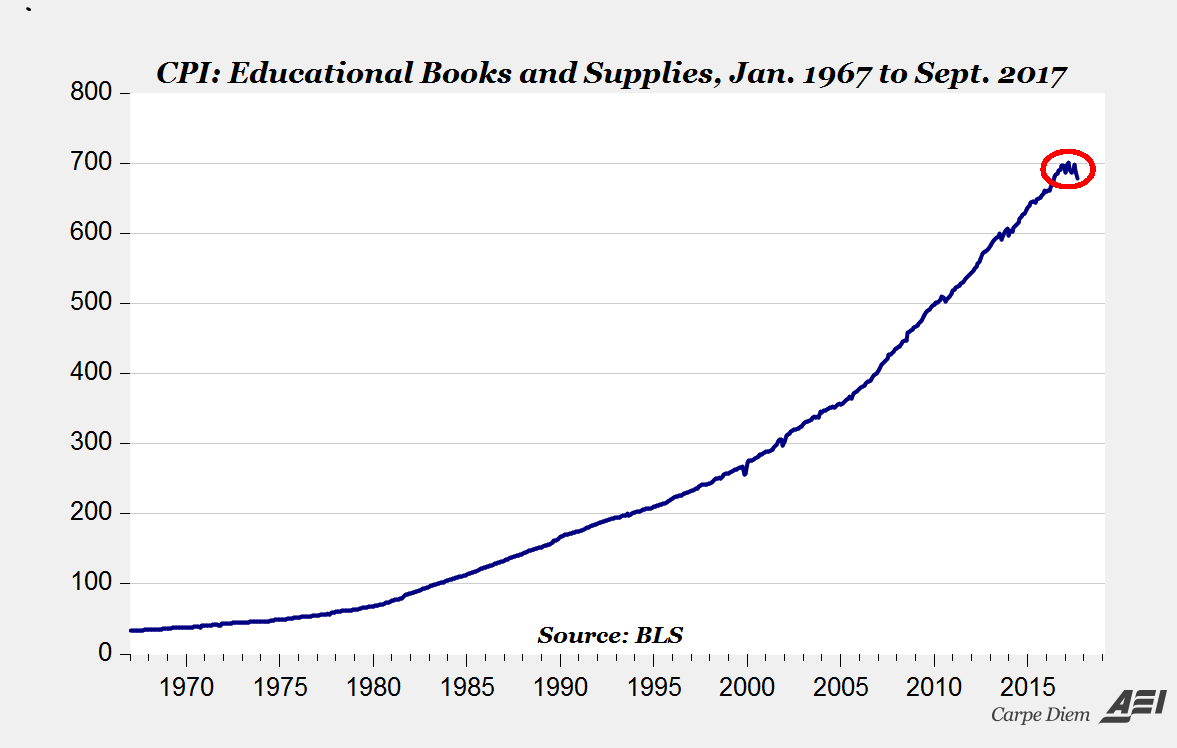
His bottom line: “I think we can expect continued disruption in the college textbook market and a continued downward trend in college textbook prices as competitive forces and more alternatives continue to erode the power of traditional textbook publishers. The trend has been broken, and college students can expect lower and lower textbook prices in the future.”
Read the entire blog entry